VALUE
Value Proposition
TECHNOLOGY Technology Overview
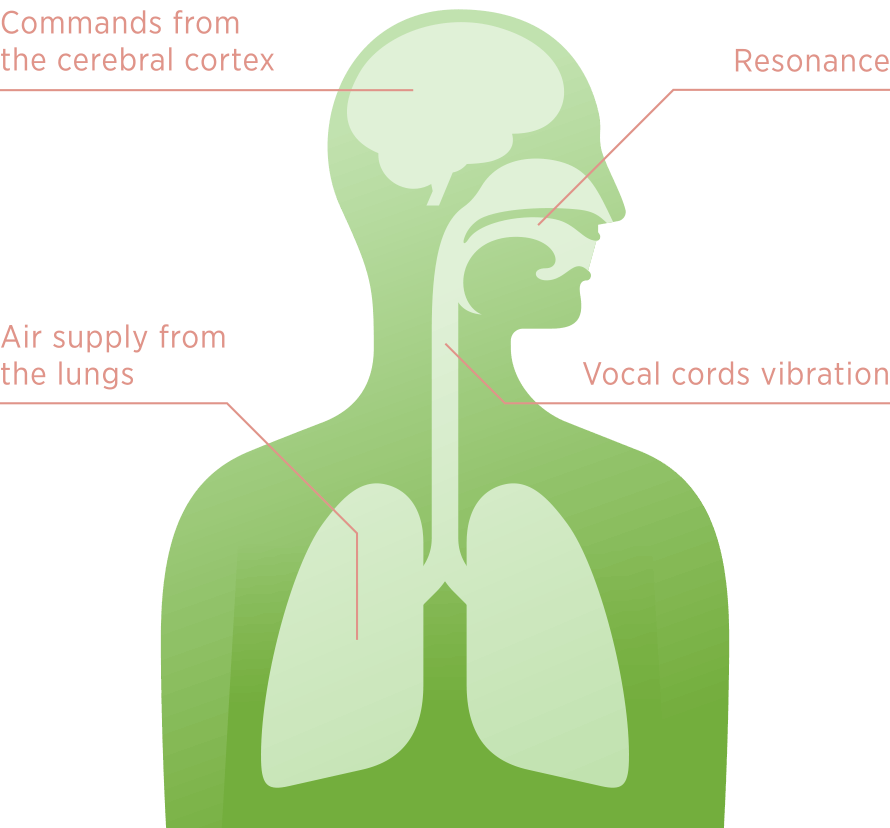
How do we generate our voice?
Voice is generated when “air (exhalation)” supplied by the lungs causes the vocal cords to vibrate, producing a “vocal cord vibration sound,” which is the basis of voice. Then, this sound is modified by “resonance” as it passes through the vocal tract to the outside, generating the voice. These three elements (expiratory flow, vocal cord vibration, and resonance) form the voice we usually hear. In addition, the fundamental tone of voice is produced when commands from the brain (cerebral cortex) are transmitted via the autonomic nervous system to the laryngeal part to control the contraction and vibration of the muscles connected to the vocal cords.
How can we grasp your pathological conditions* from your voice?
Many of the physical and mental changes caused by disease, stress, or other factors affect the elements that generate the voice, and manifest themselves as “voice symptoms.” The physical characteristics of the voice that are expressed in numerical values are called “features,” and one of these features is the “fundamental frequency.” The fundamental frequency is a variable that describes the number of times the vocal cords vibrate per second, and it is affected by factors such as the tension of the vocal cords. There is another feature called the “formant.” The “formant” is a variable based on the resonance frequency in the voice, which varies depending on the condition of the vocal tract, and it is affected by factors such as vocal tract shape, swelling, secretions, and dysarthria. By collecting and analyzing these features and others, we are able to capture “voice symptoms” manifested as physical and mental changes attributable to disease, stress, or other factors.
In addition, to better detect “voice symptoms” attributable to organic, functional, neurological, and psychological alterations, we have extracted a huge number of features assigned with a variety of data tailored to the expertise of medical professionals and the pathological conditions* to be monitored through voice sampling* by deliberately designing speech contents and vocalization tasks according to each symptom.
In other words, your pathological conditions* can be identified from your voice by analyzing the features, or the physical characteristics of your voice expressed in numerical values.
*: “voice sampling” is a term coined by PST, which means collecting voice similar to collecting or sampling blood.
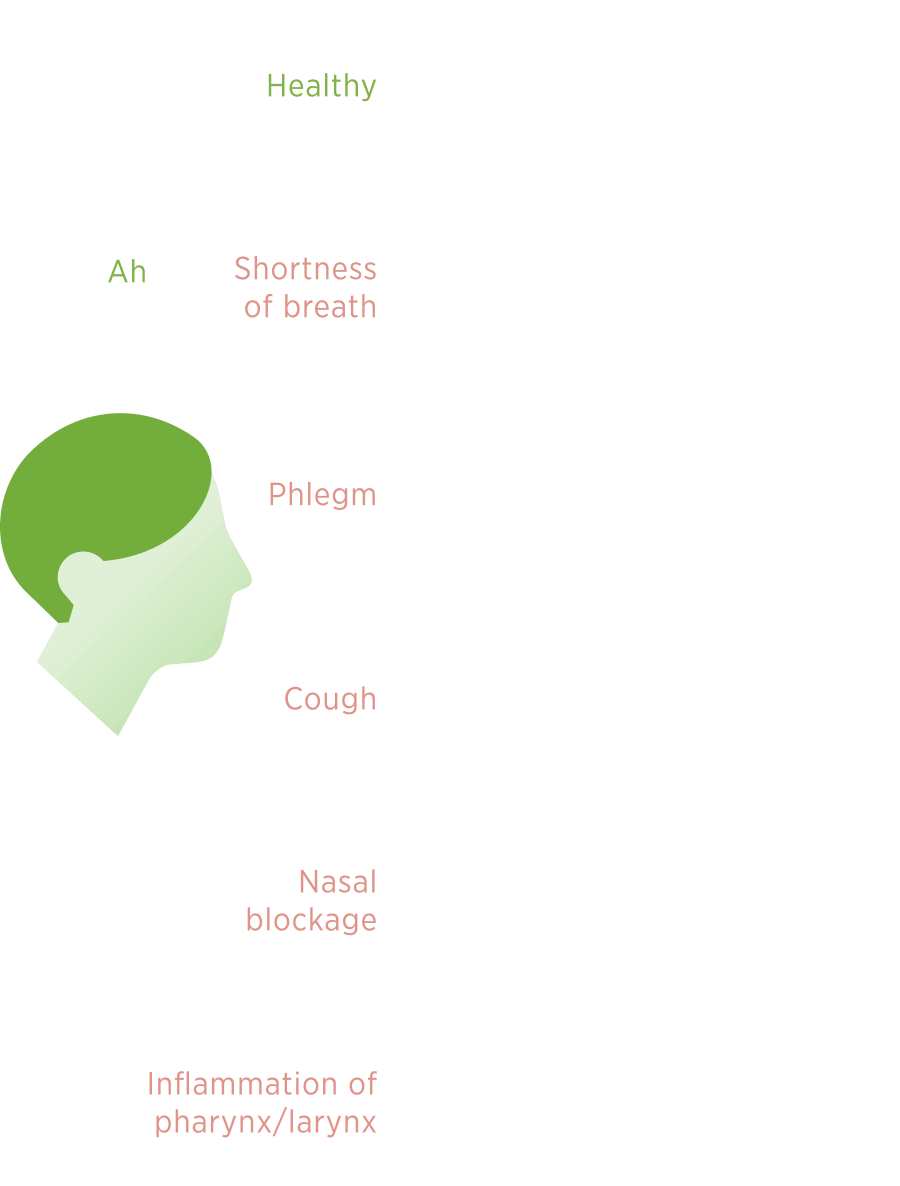
Application of machine learning/deep learning for more accurate predictions from more data
The characteristics of voice that have a clear relationship with physical and mental conditions and various symptoms of disease are important factors (acoustic features) in predicting health status. However, there is a nonlinear relationship between symptoms and acoustic features, as well as complex interactions among features. In other words, it is difficult to predict symptoms with a simple formula such as “a 5% decrease in a feature will result in a 5% decrease in expiratory flow.” Therefore, the optimal way (model) to multiply acoustic features for predicting symptoms is determined by a technique called machine learning.
Furthermore, acoustic features that cannot be easily interpreted or defined by humans may be useful in differentiating pathological conditions.* To derive features in this way, we use a technique called deep learning. By training the system with a huge amount of voice data and correct labels (presence/absence and severity of symptoms) as input, we derive the optimal model and features for prediction.
PST combines these proprietary technologies with state-of-the-art learning functionality to enable visualization of physical and mental changes attributable to disease, stress, and other factors from the “voice.”
*: Pathological conditions: Disease-specific voice symptoms




