VALUE
価値提供
TECHNOLOGY 技術概要
声を生み出す仕組み
声は、肺から送り出される “空気(呼気)” により声帯が振動することによって声の基 (もと)となる “声帯振動音” を生み、それが声道を通って外に出る間の “共鳴” によって修飾され、作り出されます。これら3つの要素(呼気流、声帯振動、共鳴)が、 普段私たちが耳にしている声を形作っているのです。また、声の原音は、脳(大脳皮質) からの指令が自律神経系を介して喉頭部へと伝えられ、声帯に繋がる筋肉の収縮をコントロールし震わせることで作り出されます。
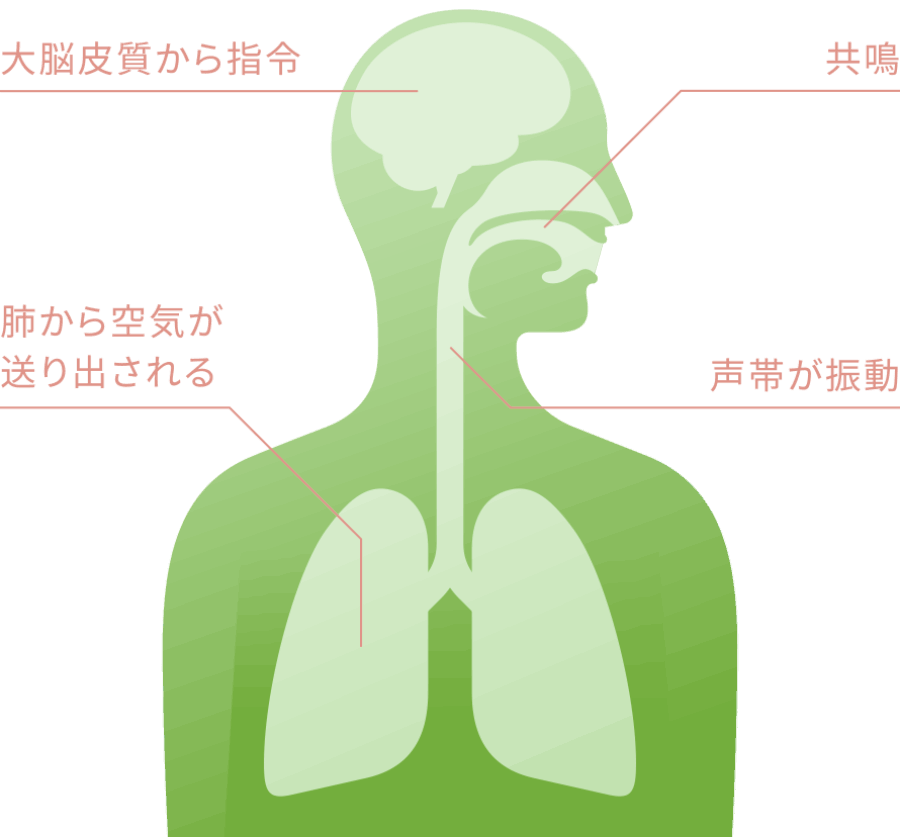
なぜ声から病態※がわかる?
病気やストレス等による心身の変化の多くは、声を生み出す要素に影響を及ぼし、“声の症状” として発現します。 声の物理的な特性を数値化したものを特徴量と言い、その特徴量の1つに「基本周波数」があります。「基本周波数」は、声帯の振動が1秒間に何回振動しているかを表した変数で、声帯の緊張度などの影響を受けます。また、他にも「フォルマント」 があります。「フォルマント」は、声道の状態により変化する声に含まれる共振周波数に基づいた変数で、声道の形状やむくみ、分泌物、構音異常などの影響を受けます。これらを含む特徴量を収集・分析することで、病気やストレスなどによる心身の変化として発現する “声の症状” を捉えています。
さらに、器質的・機能的・神経的・心理的な変調による “声の症状” をより検知するために、各症状に合わせて発話内容や発声タスクなどを工夫して採声※し、医療従事者らの知見や観測する病態※に合わせた多種多様なデータを付与した膨大な数の特徴量を抽出しています。
つまり、声の物理的な特性を数値化した特徴量を分析することで、声から病態※を判別することができます。
※:採声(さいせい): 血液を採取(採血)するように、音声を採取することを意味する PST の造語

より多くのデータから、より的確な予測のための機械学習 / 深層学習の活用
心身の状態や病気の諸症状との関係性が明らかな音声の特徴は、健康状態を予測するうえで重要な要素(音響特徴量)となります。ただし、症状と音響特徴量の間には非線形な関係があり、また特徴量同士の間にも複雑な交互作用があります。 つまり、「ある特徴量の値が5%低下すると、呼気流量も5%低下する」といったシンプルな式で症状を予測することは困難なのです。そこで、症状を予測するのに最適な音響特徴量の掛け合わせ方(モデル)を、機械学習という手法によって算出しています。
さらに、人には容易に解釈・定義できない音響特徴量が、病態※の判別に役立つ場合もあります。このような特徴量の導出には、深層学習という手法を活用します。膨大な音声データと正解ラベル(症状の有無や重症度)をインプットとして与え学習させることで、予測に最適なモデルと特徴量を導出します。
PSTはこれら独自技術と最新の学習機能を組み合わせ、“声” から病気やストレスなどによる心身の変化を可視化することを可能にしました。
※病態:疾患特異的な音声症状




